您是否正面临这些困扰?
在批量获取网站联系方式的过程中,这些痛点是否正在拖慢您的工作效率
手动查找效率极低
需要逐个打开网站寻找邮箱和电话等联系方式,面对上百甚至上千个域名,手动操作耗时耗力,严重影响工作进度。
联系方式分散难找
网站的邮箱、电话等信息可能藏在首页、关于我们、联系页面等不同位置,人工逐页查找容易遗漏关键信息。
海外网站访问受限
外贸客户开发需要采集大量海外网站的联系方式,但网络环境限制导致访问困难,缺少便捷的代理配置方案。
数据整理导出麻烦
采集到的联系方式散落在各处,缺少统一的格式化输出,后续的筛选、去重和分析工作变得异常繁琐。
核心功能与优势
专为批量采集网站邮箱和联系方式设计,让域名信息提取变得简单高效
全面提取多种联系方式
自动从网站中提取邮箱地址、电话号码、微信号、QQ号、社交媒体链接(Facebook、LinkedIn、Twitter等)以及即时通讯链接(Telegram、WhatsApp等),一次采集获取全部联系渠道。
智能识别联系页面
不仅采集首页信息,还能自动识别网站中的"联系我们""关于我们""Contact""About"等页面并深入采集,大幅提高联系方式的发现率,减少信息遗漏。
多线程并发高速采集
支持自定义并发数量,可同时处理多个网站请求,配合请求延时和重试机制,在保证稳定性的同时大幅提升采集速度,轻松应对上万域名的批量任务。
代理设置与连接测试
内置HTTP代理配置功能,一键启用代理并填写地址即可使用。提供代理连接测试按钮,确保网络通畅后再开始采集,特别适合采集海外网站的外贸用户。
JS动态渲染页面采集
部分网站的联系方式通过前端动态加载,普通请求无法获取。开启JS渲染模式后,软件会模拟浏览器执行页面脚本,确保动态内容也能被完整采集。
多格式导出与数据库存储
采集结果支持导出为CSV、Excel、TXT三种本地文件格式,也可直接写入MySQL远程数据库。自动建表补字段,无需手动配置,方便后续数据分析与管理。
采集结果字段说明
每个域名采集完成后,将输出以下16个维度的详细信息
| 字段名称 | 说明 |
|---|---|
| 域名 | 输入的原始域名 |
| 首页URL | 程序首次尝试访问的URL地址 |
| 最终URL | 经过重定向后实际访问到的URL |
| HTTP状态 | 网站返回的HTTP状态码(如200、301、404等) |
| 网站标题 | 网站首页的Title标签内容 |
| 邮箱 | 从页面文本和mailto链接中提取的邮箱地址 |
| 微信 | 从页面中识别到的微信号信息 |
| 电话/国际电话 | 从页面文本和tel链接中提取的电话号码 |
| 从页面中识别到的QQ号码 | |
| 社交媒体 | Facebook、LinkedIn、Twitter、Instagram等社交平台链接 |
| 即时通讯 | Telegram、WhatsApp、Skype、Line等即时通讯链接 |
| 采集状态 | 成功、请求失败、解析异常、任务超时等状态标识 |
| 错误原因 | 采集失败时记录的具体错误信息 |
| 采集时间 | 该条记录的采集完成时间 |
谁在使用这款工具?
覆盖多种职业场景,让不同岗位的网站联系方式采集工作更轻松
外贸业务员
根据目标市场的企业域名列表,批量采集海外客户的邮箱和社交媒体联系方式,快速建立潜在客户数据库,提升外贸开发信的触达效率。
企业营销推广
批量获取行业相关网站的联系方式,用于商务合作洽谈、广告投放对接、资源互换等营销推广活动,拓展业务合作渠道。
市场调研分析
采集竞品或行业网站的公开信息,包括网站标题、联系方式、社交媒体布局等,为市场分析报告和竞争情报收集提供数据支撑。
商务BD拓展
快速获取目标合作伙伴网站的联系邮箱和即时通讯方式,缩短商务对接的前期准备时间,让BD工作更加高效精准。
使用说明
简单几步,轻松完成网站邮箱和联系方式的批量采集
准备域名文件
准备一个TXT纯文本文件,每行填写一个域名或URL。支持多种格式,如 example.com、www.example.com、https://example.com,程序会自动识别并尝试多种访问方式(https/http、带www/不带www)。
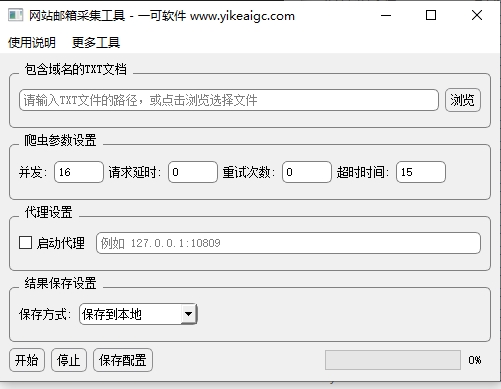
导入域名文件
打开软件后,点击"浏览"按钮选择准备好的TXT文件,或直接在输入框中填写文件路径。软件会自动读取文件中的所有域名并去重。
配置采集参数
根据需要调整爬虫参数:并发数控制同时请求的网站数量(默认10);请求延时控制访问频率;重试次数用于网络失败后重试;超时时间限制单次请求等待时长;处理超时限制单个网站的解析时间;全局超时限制整批任务的最长运行时间。
设置代理(可选)
如需采集海外网站,勾选"启动代理"并填写代理地址(如 127.0.0.1:10809)。点击"测试代理"按钮可验证代理连接是否正常。未填写协议前缀时,程序会自动按 http:// 处理。
选择保存方式
选择"保存到本地"可将结果导出为CSV、Excel或TXT文件;选择"保存到远程数据库"可直接写入MySQL数据库(需填写连接信息并测试连接)。CSV和Excel格式更适合后续筛选和分析。
开始采集
点击"开始"按钮启动采集任务,进度条会实时显示处理进度和已完成的域名数量。采集过程中可随时点击"停止"安全终止任务,已采集的数据会自动保存。完成后可在指定位置查看结果文件。