软件截图
一键获取目标网站链接中的所有主页地址,轻松掌握潜在客户资源
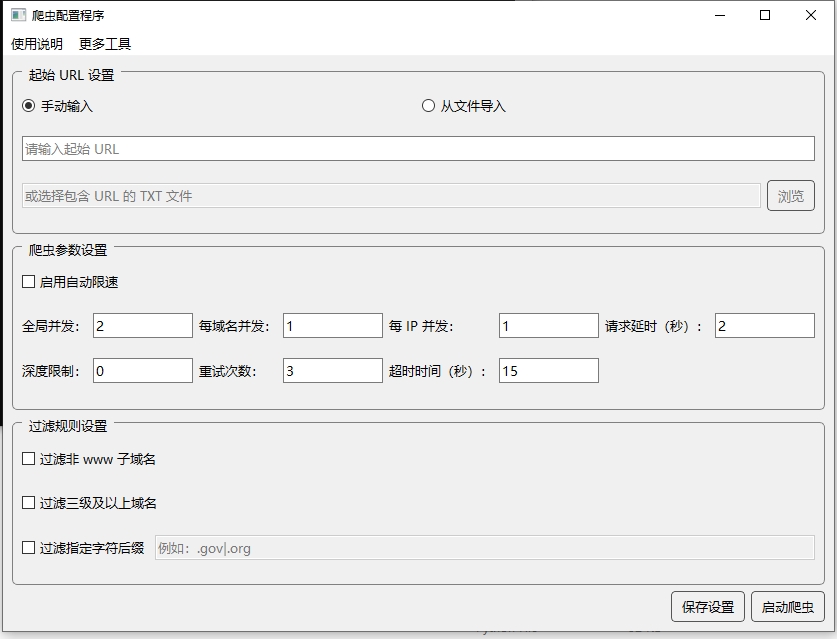
从一个或多个起始网址开始,自动爬取并提取所有外部链接的主页地址,无需手动操作,只需一键启动即可完成大量网站主页地址的采集。
支持多种过滤规则,可过滤非www子域名、三级及以上域名、特定后缀的URL等,确保采集结果更加精准,符合您的具体需求。
可自定义爬虫的并发数、请求延时、爬取深度、重试次数等参数,按需调整爬取效率和服务器负载,避免IP被封禁。
支持从TXT文件批量导入起始URL,每行一个地址,方便对大量已有网址资源进行扩展爬取,大幅提高工作效率。
内置自动限速功能,根据目标网站的响应情况智能调整请求频率,既保证爬取效率又降低被屏蔽风险,实现长时间稳定采集。
采集的URL会实时保存到output.txt文件中,每100条刷新一次,即使程序意外关闭也不会丢失已采集的数据,确保您的工作成果安全可靠。
营销人员可以通过本工具快速收集行业内潜在客户的网站地址,为后续的邮件营销、电话销售等活动提供大量有效的目标企业联系渠道。
从行业门户网站爬取相关企业网址,方便企业对同行业竞争对手进行全面分析,了解市场格局,为战略决策提供数据支持。
SEO优化人员可利用本工具收集行业相关网站地址,进行有针对性的外链建设和友情链接交换,提升网站权重和搜索引擎排名。
数据分析师可以先使用本工具采集目标网站地址,为后续的网站内容采集、信息提取、数据分析等工作准备基础的URL资源库。
手动输入单个网址,或点击"浏览"按钮导入包含多个URL的TXT文件(每行一个URL)。如果URL不包含http://或https://前缀,系统会自动添加http://前缀。
根据需要设置全局并发数、每域名并发数、每IP并发数、请求延时、爬取深度限制、重试次数和超时时间。如果不确定,可以勾选"启用自动限速",系统会自动调整相关参数。
根据需要勾选以下过滤选项:
- 过滤非www子域名:只保留www开头的网站主页
- 过滤三级及以上域名:过滤掉形如news.example.com的网站
- 过滤指定字符后缀:输入要过滤的后缀,如.gov|.org,多个后缀用|分隔
点击"保存设置"按钮将当前配置保存到config.json文件,以便下次使用。然后点击"启动爬虫"按钮开始采集过程。采集的URL会实时保存到output.txt文件中。
爬虫运行过程中或结束后,可以打开当前目录下的output.txt文件查看采集结果。每行一个URL,格式为http://domain.com或https://domain.com。