功能特点
智能爬虫技术
采用先进的网络爬虫技术,自动深度爬取网站内容,精准识别并提取页面中的手机号码
精准筛选功能
支持手机号前缀筛选和标题关键词黑名单设置,只采集您真正需要的目标号码数据
高效并发采集
多线程并发爬取技术,可根据电脑性能和网络情况调整采集线程数,提高数据采集速度
灵活数据保存
支持本地文件保存和远程数据库保存两种方式,满足不同场景下的数据存储需求
持续运行机制
设计为长期挂机运行模式,自动清理访问记录缓存,定期切换输出文件,保障稳定运行
UA模拟与配置
支持自定义UA浏览器标识,有效规避网站反爬虫机制,提高采集成功率
应用场景
商业应用
- 市场调研:采集特定行业或地区企业的联系电话,为市场调研提供数据支持
- 客户开发:获取潜在客户联系方式,扩大销售网络,提高业务转化率
- 行业分析:收集特定行业网站的联系电话,进行行业数据分析和统计
- 企业宣传:获取目标客户手机号码,进行短信营销或电话推广
个人使用
- 人脉拓展:收集特定领域的联系人手机号码,扩展个人人脉网络
- 求职应聘:采集招聘网站的HR联系电话,提高求职效率
- 学术研究:收集研究对象的联系方式,用于问卷调查或访谈
- 资源整合:批量采集并整理相关领域的联系人信息
使用指南
-
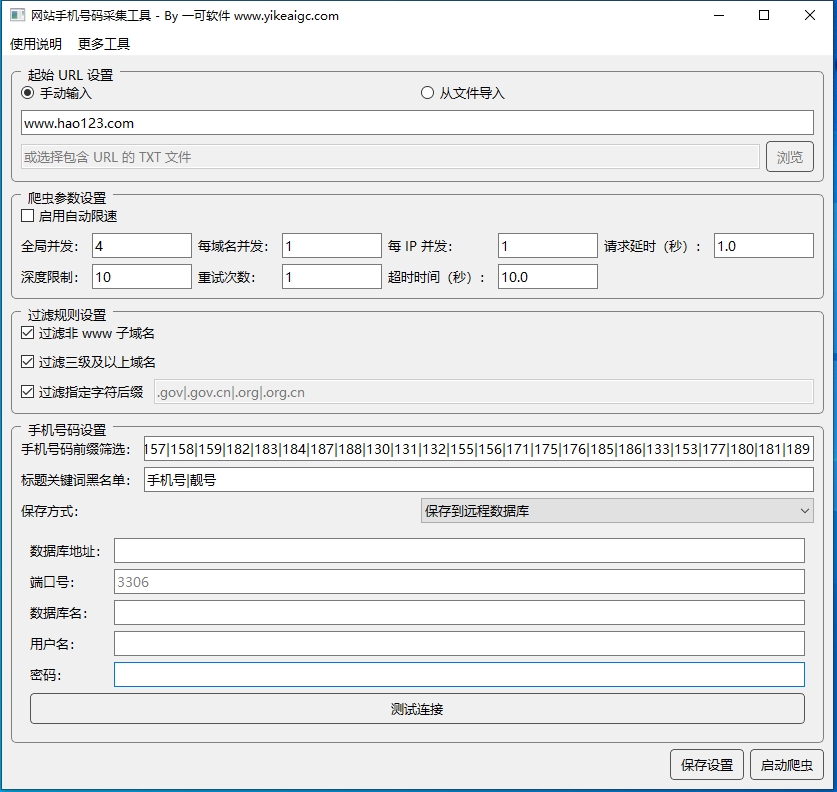
准备起始URL文件
创建一个文本文件,将需要采集的网站域名或URL列表写入,每行一个。这些URL将作为爬虫的起始点,程序会从这些URL开始爬取手机号码。
-
配置采集参数
在软件界面中选择起始URL文件,可选地设置UA文件(用于模拟不同浏览器访问)、线程数量(建议5-20,视网络情况调整)、是否过滤非www子域名等参数。
-
设置筛选条件
根据需要,设置手机号前缀筛选(例如:135|136|137)和标题关键词黑名单,只采集符合条件的手机号码数据,提高数据质量。
-
选择保存方式
选择数据保存方式,可以保存到本地文本文件或远程MySQL数据库。如选择数据库保存,需配置正确的数据库连接信息。
-
开始采集
点击"开始"按钮,软件将自动开始采集过程。采集过程中,可以在日志窗口实时查看采集状态和已采集的数据量。
-
管理采集结果
采集完成后,可在指定位置找到采集结果文件(格式为:网页标题----页面URL----电话号码),或在数据库中查询已保存的数据。