您是否正面临这些困扰?
文本文件对比与数据整理中常见的效率瓶颈,正在浪费您的宝贵时间
手动逐行比对效率极低
两份TXT文件各有上千行数据,需要找出差异内容,却只能用肉眼逐行对照?不仅耗时数小时,还极易遗漏关键差异,严重影响工作效率。
多份数据合并去重困难
从不同渠道收集的数据列表需要合并,但其中充斥着大量重复条目。用Excel手动去重不仅操作繁琐,面对大文件还容易卡顿崩溃。
海量文本中筛选信息难
需要从两份庞大的日志或数据文件中快速提取包含特定关键词的行,却找不到合适的工具?传统文本编辑器的查找功能远远不够用。
核心功能与优势
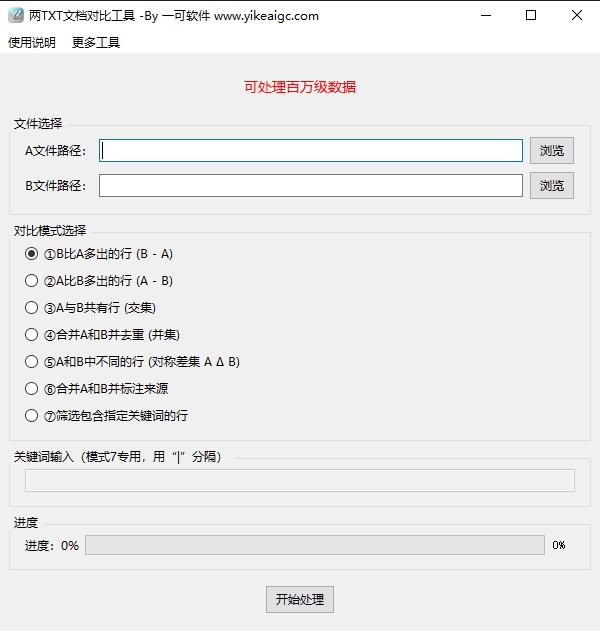
七种专业对比模式,覆盖TXT文件差异比较、去重合并、关键词筛选等全部需求
多种差集运算模式
一键找出文件B比A多出的行,或A比B多出的行,精准定位两个TXT文件之间的内容差异,无需逐行人工比对,节省90%以上的核对时间。
交集并集对称差集
支持提取两个文件的共有行(交集)、合并去重(并集)、仅存在于其中一个文件的行(对称差集),满足各类集合运算需求。
合并文件并标注来源
将两个TXT文件的全部内容合并为一个文件,并在每行末尾自动标注数据来源(A或B),方便后续追溯和分类整理。
关键词批量筛选去重
输入一个或多个关键词,从两个文件中快速筛选出包含这些关键词的所有行并自动去重,高效提取您需要的目标数据。
智能编码自动识别
自动检测TXT文件的编码格式,完美兼容UTF-8、GBK、GB18030、Big5等多种编码,无需手动设置,避免中文乱码问题。
大文件高速处理
针对大文件进行了性能优化,处理百万行级别的TXT文件依然流畅,实时进度条显示处理进度,大数据量处理不再盲等。
谁在使用这款工具?
覆盖多种职业场景,让不同岗位的文本对比与数据整理工作更轻松
数据运营人员
比较不同来源的数据列表,快速去除重复项或找出差异数据,高效完成数据清洗与去重整理工作。
开发测试人员
对比配置文件、代码片段或程序输出结果,快速定位两个版本之间的差异,辅助开发调试与版本管理。
运维管理人员
合并不同服务器或时间段的日志文件,根据关键词筛选包含特定错误信息的日志行,快速排查问题。
行政办公人员
比较新旧两份参与者名单、客户列表或通讯录,轻松找出新增、移除或重复的条目,提升名单管理效率。
使用说明
简单五步,轻松完成两个TXT文件的差异对比与数据处理
选择A文件和B文件
打开软件后,分别点击"浏览"按钮选择需要对比的两个TXT文件。也支持直接将文件拖拽到对应的输入框中,操作更便捷。
选择对比模式
在"对比模式"下拉菜单中选择您需要的处理方式:B比A多出的行(B-A差集)、A比B多出的行(A-B差集)、两者共有行(交集)、合并去重(并集)、仅存在于其中一个文件的行(对称差集)、合并并标注来源、或按关键词筛选。
设置选项(按需)
勾选"保持原文件顺序"可让结果按照原文件中的出现顺序排列。如果选择了关键词筛选模式,请在关键词输入框中填入要查找的关键词,多个关键词之间用英文竖线"|"分隔。
点击开始处理
确认文件和模式无误后,点击"开始处理"按钮。软件将自动检测文件编码并开始执行对比任务,界面上的进度条会实时显示处理进度。处理过程中可随时点击"停止"按钮中断。
获取处理结果
处理完成后会弹出提示框。结果文件自动保存在A文件所在的同一目录下,文件名为"处理结果.txt"。日志区域会显示详细的处理统计信息,包括各文件行数和结果行数。