您是否正面临这些困扰?
手动处理TXT文件中的无用行,效率低下且容易出错
海量TXT文件逐个处理太慢
面对成百上千个TXT文件,需要逐个打开、查找、删除特定行,手动操作耗时耗力,一天下来也处理不了多少。
日志和爬虫数据充满噪音
程序运行日志、爬虫抓取的文本中混杂着大量广告、空行、无效信息,严重影响后续的数据分析和使用。
删除条件复杂难以兼顾
有时需要同时按关键词、行号、字数等多种条件删除行,普通文本编辑器无法满足这种复杂的组合筛选需求。
核心功能与优势
多条件组合批量删除TXT指定行,让文本清洗变得简单高效
按关键词精准删行
支持"包含指定关键词删除"和"不含指定关键词删除"两种模式,多个关键词用竖线分隔,精准定位并批量清除含有特定内容的行。
按行号范围批量删除
输入具体行号或行号范围(如1,3,5-10),一次性删除多个指定位置的行,还支持负数行号从末尾倒数定位,灵活应对各种需求。
按字数阈值筛选删除
设置每行字数的大于、小于或等于条件,自动删除不符合长度要求的行,快速过滤掉过短的无效行或过长的异常数据。
一键清除所有空行
勾选即可自动删除文件中的所有空白行,无需手动逐行查找,让文本内容更加紧凑整洁,提升数据质量。
递归遍历子目录处理
支持一键扫描主文件夹及所有子文件夹中的TXT文件,批量处理上百个文件,还可保持原路径结构保存,为您节省90%的重复工作时间。
合并保存与自动去重
处理结果支持单独保存或合并为一个文件,合并时可自动去除重复行,方便后续统一管理和使用处理后的文本数据。
谁在使用这款工具?
覆盖多种职业场景,让不同岗位的TXT文本清洗工作更轻松
运维工程师
快速清理服务器运行日志中的调试信息和冗余记录,只保留关键错误和警告行,提升日志分析效率。
爬虫开发者
对网络爬虫抓取的原始文本进行预处理,批量删除广告、导航链接、空行等无效内容,获取干净的数据。
内容编辑人员
批量整理文章素材和文档,删除包含特定标记、过时信息或格式错误的行,快速完成大量文本的编辑工作。
数据分析师
清洗采集到的原始文本数据集,去除格式异常、内容无效或不符合长度要求的行,提高数据质量和分析准确性。
使用说明
简单五步,轻松完成TXT文件批量删除指定行
选择源文件夹
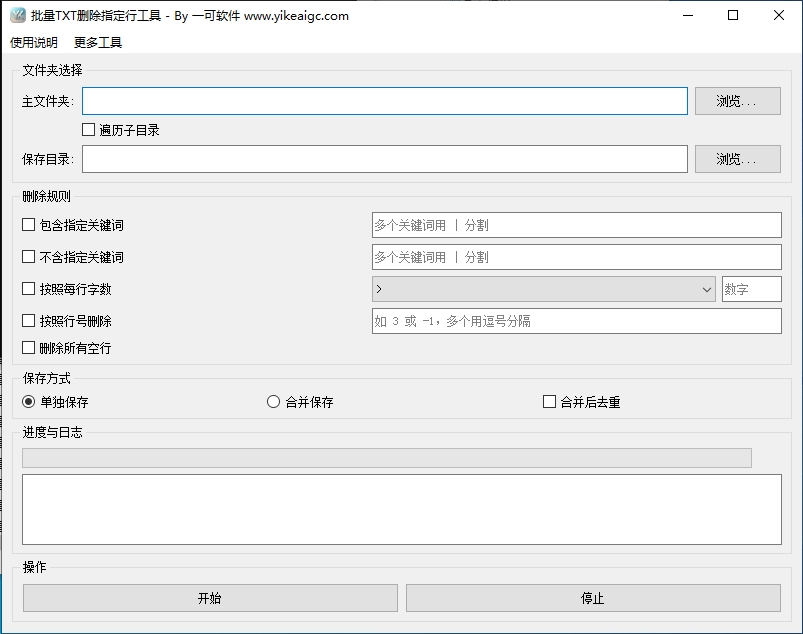
点击"浏览"按钮选择存放TXT文件的文件夹,也可以直接将文件夹拖拽到输入框中。如果TXT文件分散在多层子目录中,请勾选"遍历子目录",软件会自动扫描所有层级的文件。
指定保存位置
点击"浏览"按钮选择处理后文件的保存目录。如果勾选了"遍历子目录",还可以勾选"保持原路径结构",让输出文件与源文件保持相同的目录层级关系。
设置删除规则
根据需要勾选并配置一种或多种删除条件:在"包含"或"不含"输入框填入关键词(多个用"|"分隔);选择字数条件(大于/小于/等于)并输入数值;输入要删除的行号(如1,3,5-10);或直接勾选"删除空行"。所有条件可自由组合同时生效。
选择保存方式
选择"单独保存"则每个TXT文件处理后生成一个对应的新文件;选择"合并保存"则所有文件处理后的内容合并为一个文件。合并保存时还可以勾选"合并后去重",自动删除重复行。
开始处理
点击"开始"按钮,软件将自动批量处理所有TXT文件。处理过程中可以实时查看进度条和日志信息,如需中途停止可随时点击"停止"按钮。处理完成后会弹出统计报告,显示总文件数、删除行数等详细数据。