您是否正在被这些音频处理难题困扰?
无论是制作K歌伴奏、净化嘈杂录音还是提取视频配音,传统方式都在浪费您的宝贵时间
想要纯伴奏却只能找到原唱
网上搜不到想要歌曲的纯伴奏版本,在线工具分离效果差、有水印,还担心版权音频被上传到第三方服务器泄露隐私。
录音嘈杂有回声难以使用
播客、直播、会议录音中混杂大量背景噪声和回声混响,人声模糊不清,后期剪辑时无法直接使用。
上百首歌曲需要逐个处理
手头有大量音频文件需要分离人声或伴奏,一首一首手动操作效率极低,急需能批量处理整个文件夹的工具。
视频中的配音无法单独提取
想从视频素材中提取干净的旁白或对话音轨,却苦于没有简单易用的工具能直接从视频文件中分离人声。
AI驱动的专业音频人声分离与录音降噪
多种AI模型覆盖音乐分离与录音净化两大场景,批量处理为您节省90%的重复工作时间
音乐人声伴奏分离
一键将歌曲精准分离为干净的人声轨和纯伴奏轨,轻松获取高质量卡拉OK伴奏或纯人声清唱,满足翻唱、混音、采样等创作需求。
录音降噪提取清晰人声
针对播客、直播、会议等含背景噪声的录音,智能去除环境杂音并提取清晰人声,让嘈杂录音变得干净可用。
去回声去混响处理
专门消除人声中的回声与混响效果,配合降噪模型二段串联使用,从空旷房间录音中还原贴麦般的干净人声。
批量处理整个文件夹
支持一次性导入整个音频文件夹批量分离,递归遍历子目录处理多层级歌曲库,一次操作处理上百首音频,效率提升数十倍。
二段串联深度净化
开启二段处理后,第一阶段提取人声,第二阶段自动对人声做去回声去混响净化,两步串联一键完成,无需手动重复操作。
20+音频视频格式支持
输入支持MP3、WAV、FLAC、M4A、AAC、OGG、OPUS、WMA等音频格式,也支持MP4、MKV、MOV等视频文件直接提取音轨分离。
多种AI模型覆盖不同音频分离场景
根据您的实际需求选择最合适的处理模式,一键切换即可获得最佳分离效果
音乐人声分离 - 高质量
音乐人声/伴奏分离的主力模型,质量与速度均衡,适合绝大多数歌曲的人声伴奏分离任务。
- 人声干净无残留伴奏
- 伴奏完整无人声泄漏
- 处理速度与质量均衡
录音降噪 + 提取人声
针对录音、直播、播客等含背景噪声的音频,智能去除环境杂音并提取清晰人声。
- 去除风噪、空调声等环境噪声
- 保留人声自然音色
- 适合播客/会议/直播录音
去回声 / 去混响
专门消除人声中的回声与混响效果,配合降噪模型串联使用可获得贴麦般的干净人声。
- 消除空旷房间回声
- 去除混响拖尾效果
- 可与降噪模型二段串联
三种输出格式满足不同品质需求
根据您的用途自由选择无损或有损格式,兼顾音质与文件体积
WAV 无损格式
无压缩无损音质,适合后期混音、专业制作、音乐采样等对音质要求极高的场景,推荐首选。
FLAC 无损压缩
无损压缩格式,音质与WAV相同但文件体积更小,适合归档存储大量分离后的音频文件。
MP3 通用格式
兼容性最广、体积最小的有损格式,适合K歌伴奏分享、社交媒体发布、手机播放等日常使用场景。
谁在用这款批量音频人声分离工具?
覆盖音乐制作、内容创作、教育培训、商业录音等多个领域,让不同岗位的音频处理工作更轻松
K歌爱好者
从任意歌曲中提取纯伴奏用于K歌练唱,也可提取人声学习唱法技巧,不再受限于有限的卡拉OK曲库。
播客 / 直播主播
对嘈杂环境下的录音进行降噪净化,去除背景杂音和回声,让播客音频和直播回放听起来更专业清晰。
音乐制作人 / DJ
提取歌曲中的人声或乐器音轨用于混音、采样、Remix创作,批量处理素材库中的大量音频文件。
视频创作者
从视频素材中提取干净的旁白或对话音轨,去除背景音乐干扰,方便后期配音替换或字幕制作。
教育培训
净化课堂录音、讲座音频中的环境噪声,提取清晰的讲师人声用于制作在线课程或学习资料。
企业会议记录
对会议录音进行降噪处理,去除空调声、键盘声等环境杂音,让会议纪要转写和回听更加清晰准确。
音频后期工程师
批量预处理大量音频素材,快速分离人声与背景音,为精细后期制作节省大量前期准备时间。
语言学习 / 听力训练
从外语歌曲或影视片段中提取纯人声对话,去除背景音乐干扰,制作沉浸式听力练习材料。
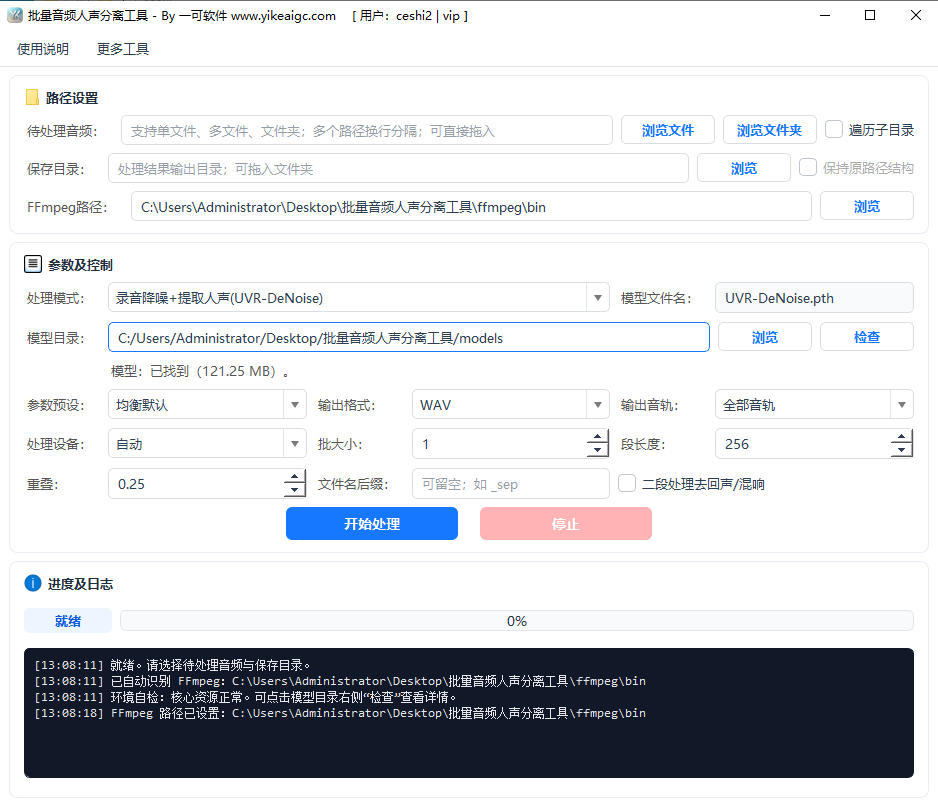
简单六步完成批量音频人声分离
新手照着做也能快速上手,所有参数可视化操作,几分钟搞定上百首音频的人声伴奏分离
选择待处理音频
点击"浏览"按钮选择需要分离的单个音频文件、多个文件或包含音频的文件夹,也支持直接将文件或文件夹拖拽到输入框中。如果想处理子文件夹中的所有音频,请勾选"遍历子目录"。
支持拖拽多个文件,也支持直接拖入视频文件提取音轨设置保存目录
选择分离后音频的保存位置,建议指定一个空文件夹方便归档。勾选"保持原路径结构"后,输出文件会按照源文件的目录层级整齐归档,方便管理大量歌曲。
保存目录与输入路径不要相同,避免文件混淆选择处理模式
根据需求选择对应的AI模型:制作K歌伴奏选"音乐人声分离"系列模型;净化嘈杂录音选"录音降噪+提取人声";消除回声选"录音去混响/去回声"。也可选择"自定义模型文件名"使用其他模型。
新手推荐使用"音乐人声分离 - 推荐"模型,效果最均衡设置输出格式与音轨选择
选择输出格式(WAV无损/FLAC无损压缩/MP3通用),再选择输出哪些音轨:仅人声、仅伴奏或全部音轨都保留。K歌伴奏选"仅伴奏",提取人声选"仅人声"。
推荐输出WAV格式,避免重复编码导致音质损失调整高级参数(可选)
可通过"参数预设"快速切换为均衡默认、速度优先、质量优先、低内存或GPU高速模式。也可手动调整处理设备、批大小、段长度、重叠等参数。对于嘈杂录音,可开启"二段处理"进行深度净化。
新手直接使用默认参数即可,无需手动调整点击"开始处理"
一切就绪后点击"开始处理"按钮,软件会自动识别并批量处理所有音频文件,进度条与日志实时反馈处理状态。处理结束后前往保存目录查看分离结果,即可直接使用。
处理过程中可随时点击"停止"安全中断任务使用前最关心的疑问都在这里
关于音频人声分离、录音降噪、批量处理、输出格式等高频问题一次说清